 观点知讯
2024-02-21
观点知讯
2024-02-21
2月18日,根据《互联网信息服务深度合成管理规定》,国家互联网信息办公室公开发布第四批境内深度合成服务算法备案信息,“智慧芽文本生成大模型算法”成功通过备案(备案编号:网信算备320508893984201240017号)。智慧芽成为业内率先获得国家网信办大模型算法备案的企业。
基于高质量的数据和领先的算法技术优势,智慧芽已成功训练专注知识产权领域的“PatentGPT”和专注于医药领域的“PharmGPT”两款垂直领域大模型,致力于为知识产权、研发创新、生物医药等应用场景提供高效的信息检索、分析和应用体验,颠覆传统科创信息获取和服务范式,显著提升科技创新效能。
PatentGPT达到了通过中国专利代理师资格考试的水平,PharmGPT达到了通过中国执业药师职业资格考试、美国注册药剂师考试(NAPLEX)的水平,部分能力超越GPT-4。
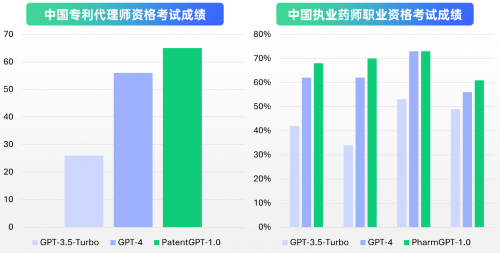
图:智慧芽大模型考试成绩
此外,在MMLU(Massive Multitask Language Understanding)、C-eval,以及智慧芽面向业内首次提出的专利大模型测试基准(patent-bench)的测评结果显示,智慧芽大模型在问答、总结、写作、翻译、分类等方面能力皆优于商业通用大模型。
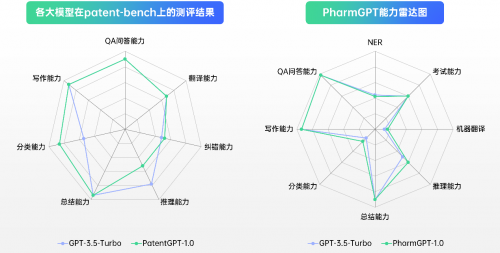
图:智慧芽大模型能力测评
“海量垂域数据+AI算法积累”夯实大模型底座
智慧芽AI大模型的成功应用,离不开底层海量优质数据资源的积累,以及十余年AI算法技术研发的沉淀。
海量高质量的垂直行业数据集:智慧芽PatentGPT和PharmGPT的成功建立在庞大的、高质量的垂直行业数据集之上,其预训练数据达到了千亿级token的规模。上述训练数据既包含了智慧芽十余年积累和深加工的全球170个受理局的超过1.8亿专利、超过1.6亿篇论文、超过2100万则新闻、超过8.6亿个生物序列、超过2.5亿个化学结构、超过4万种靶点、超过8万种新药数据等。在智慧芽垂直领域独特的数据配方构成上,还加入了7000余本专业书籍、丰富的行业常识等内容。

图:智慧芽大模型预训练数据示意图
垂直领域AI算法积累与持续迭代:智慧芽在专利、生物医药等行业的AI算法领域有着丰厚的技术积累,在过去十余年间成功采用计算机视觉、机器学习、自然语言处理、神经网络、OCR识别、知识图谱、大模型技术等处理和分析各类数据,辅助用户进行创新决策。其中,智慧芽AI算法团队曾构筑了数十种Bert模型以清洗、处理数据,为自研大模型的训练奠定了坚实基础。
针对大模型训练,智慧芽围绕数据、算法训练、测试、强化学习构筑了四大平台。智慧芽采用了增强式预训练的策略,基于专利和医药领域超40位专家反馈及其2万多条对比数据的强化学习,配合RAG(Retrieval-Augmented Generation检索增强生成)加强大模型理解能力,减少幻觉,对齐人类意图,将大模型精度提升至80%。
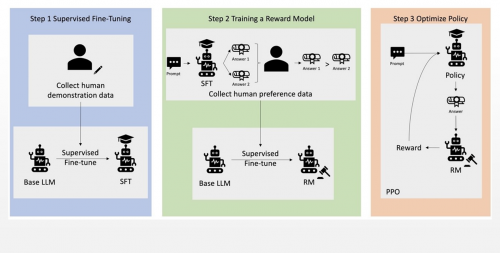
图:基于专家反馈的强化学习
目前,基于智慧芽大模型技术的多项AI功能已上线智慧芽各产品,受到了用户的广泛好评。在智慧芽研发情报库Eureka中用户通过AI技术问答可以实现自然对话的方式,输入技术问题或关键词后,即可获得经过整理汇总的相关技术方案。在智慧芽新药情报库Synapse中,用户可通过医药情报助手一键生成详尽的药物调研报告,还可提炼总结核心信息,将所选英文内容翻译成中文,或解释生物医药术语等。





